

 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[多选题]
我们想要训练一个ML模型,样本数量有100万个,特征维度是5000,面对如此大数据,如何有效地训练模型()。
A.对训练集随机采样,在随机采样的数据上建立模型
B.尝试使用在线机器学习算法
C.使用PCA算法减少特征维度
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
A.对训练集随机采样,在随机采样的数据上建立模型
B.尝试使用在线机器学习算法
C.使用PCA算法减少特征维度
答案
 更多“我们想要训练一个ML模型,样本数量有100万个,特征维度是5000,面对如此大数据,如何有效地训练模型()。”相关的问题
更多“我们想要训练一个ML模型,样本数量有100万个,特征维度是5000,面对如此大数据,如何有效地训练模型()。”相关的问题
第1题
A.使用前向特征选择方法
B.使用后向特征排除方法
C.我们先把所有特征都使用,去训练一个模型,得到测试集上的表现.然后我们去掉一个特征,再去训练,用交叉验证看看测试集上的表现.如果表现比原来还要好,我们可以去除这个特征
D.查看相关性表,去除相关性最高的一些特征
第2题
(i)一个学区中学校的最多数量和最少数量是多少?每个学区的学校平均数量是多少?
(ii)利用混合OLS(即将所有1848个学校混合在一起),估计一个将lavgsal与bs,lenrol,lstaff和lunch相联系的模型:也参见第9章的计算机练习C11。bs的系数和标准误是多少?
(iii)求对学区内聚类相关(和异方差性)保持稳健的标准误。bs的t统计量有何变化?
(iv)去掉bs>0.5的四个观测,仍用混合OLS,求出βbs及其聚类稳健标准误。现在,薪水与福利之间的替代关系,有更多的证据吗?
(v)容许一个学区内的学校存在一个共同的学区效应,用固定效应法估计这个方程。再次去掉bs>0.5的四个观测,现在,你对薪水与福利之间的替代关系有何结论?
(vi)根据你在第(iv)部分和第(v)部分的估计值,讨论通过学区固定效应而容许教师的薪酬在不同学区系统变化的重要性。
第3题
A.第1个模型的训练误差大于第2个、第3个模型
B.最好的模型是第3个,因为它的训练误差最小
C.第2个模型最为“健壮”,因为它对未知样本的拟合效果最好
D.第3个模型发生了过拟合
第5题
A.级别划分较多的属性不会影响模型效果
B.在某些噪音较大的分类或回归问题上不会过拟合
C.每次学习使用不同训练集,一定程度避免过拟合
D.能够处理高纬度的数据,并且不做特征选择
第6题
A.从数据中移除停用词(stopwords)将会影响数据的维度
B.数据中词的归一化将会减少数据的维度
C.转化所有的小写单词将不会影响数据的维度
第7题
A.样本越少,模型的方差越大
B.如果模型性能不佳,可减少样本多样性进行优化
C.增加数据可以减少模型方差
D.样本越多,模型训练越快,性能越好
第10题
A.完成一个主题模型掌握语料库中最重要的词汇
B.训练袋N-gram模型捕捉顶尖的n-gram:词汇和短语
C.训练一个词向量模型学习复制句子中的语境
D.以上所有
第11题
利用401KSUBS.RAW中的数据。
(i)计算样本中netta的平均值、标准差、最小值和最大值。
(ii)检验假设:平均netta不会因为401(k)资格状况而有所不同,使用双侧备择假设。估计差异的美元数量是多少?
(iii)根据第7章的计算机练习C7的第(ii)部分,e401k在一个简单回归模型中显然不是外生的,起码它随着收入和年龄而变化。以收入、年龄和e401k作为解释变量估计nettfa的一个多元线性回归模型。收入和年龄应该以二次函数形式出现。现在,估计401(k)资格的美元效应是多少?
(iv)在第(ii)部分估计的模型中,增加交互项e401k(age-41)和e401k-(age-41)2。注意样本中的平均年龄约为41岁,所以在新模型中,e401k的系数是401(k)资格在平均年龄处的估计效应。哪个交互项显著?
(v)比较第(iii)和(iv)部分的估计值,401(k)资格在41岁处的估计效应差别大吗?请解释。
(vi)现在,从模型中去掉交互项,但定义5个家庭规模虚拟变量:fsizel,fsize2,fsize3,fsize4和fsize5。对有5个或5个以上成员的家庭,fsize5等于1。在第(ii)部分估计的模型中,增加家庭规模虚拟变量,记得选择一个基组。这些家庭虚拟变量在1%的显著性水平上显著吗?
(vii)现在,针对模型
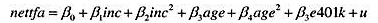
在容许截距不同的情况下,做5个家庭规模类别的邹至庄检验。约束残差平方和SSR,从第(iv)部分得到,因为那里回归假定了相同斜率。无约束残差平方和 其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。
其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。



















