

 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
在统计计算中,()算法是在概率模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量。
A.K-Means算法
B.Apriori算法
C.最大期望算法
D.KNN算法
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
A.K-Means算法
B.Apriori算法
C.最大期望算法
D.KNN算法
答案
 更多“在统计计算中,()算法是在概率模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量。”相关的问题
更多“在统计计算中,()算法是在概率模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量。”相关的问题
第2题
A.基于部分马尔科夫模型的两步决策算法
B.基于马尔科夫决策过程的强化学习决策方法
C.城市挑战赛Boss无人车应用的有限状态机
D.城市挑战赛Annieway无人车应用的分层状态机
第4题
对(许多美国工人可用的)401(k)养老金计划的出现是否提高了净储蓄,吸引了大量研究兴趣。数据集401KSUBS.RAW包含了有关净金融资产(nettfa)、家庭收入(ic)、是否有资格参与401(k)计划的二值变量(e401k)和其他几个变量的信息。
(i)样本中有资格参与一个401(k)计划的家庭比例是多少?
(ii)估计一个用收入、年龄和性别解释401(k)资格的线性概率模型。包括收入和年龄的二次项,并以通常形式报告结论。
(iii)你认为401(k)资格独立于收入和年龄吗?性别呢?请解释。
(iv)求第(ii)部分中估计的线性概率模型的拟合值。有小于0或大于1的拟合值吗?
(v)利用第(iv)部分中的拟合值e401k1,定义e401k1在e401k≥0.5时取值1,并在2e401k<0.5时取值0。在9275个家庭中,预计有多少家庭有资格参与401(k)计划?
(vi)对于没有资格参加401(k)的5638个家庭,利用预测值e401k1,预测其中有多大比例没有401(k)?对于有资格参加401(k)的3637个家庭,其中有多大比例的家庭有401(k)?(如果你的计量经济软件具有“制表”命令更好。)
(vii)总正确预测比约为64.9%。给定第(vi)部分的答案,你认为这是模型好坏的一个完备描述吗?
(viii)在线性概率模型中增加一个解释变量pira。其他条件不变,若一个家庭有某人拥有个人退休金账户,一个家庭有资格参与401(k)计划的估计概率会提高多少?在10%的显著性水平上,它统计显著异于0吗?
第5题
利用VOTE1.RAW中的数据。
(i)考虑一个含有竞选支出交互项的模型
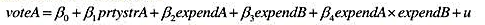
保持prtystrA和expendA不变,expendB对voteA的偏效应是什么?expendA对voteA的偏效应是什么?β4的预期符号明显吗?
(ii)估计第(i)部分中的方程,并以通常的格式报告结果。交互项是统计显著的吗?
(ii)求样本中expendA的均值。固定expendA为300(300000美元)。候选人B另外支出100000美元对voteA的估计影响是什么?这个影响很大吗?
(iv)现在固定expendB为100。AexpendA=100对voteA的估计影响是什么?这讲得通吗?
(v)现在估计一个用候选人A的支出占竞选总支出的百分比shareA取代交互作用项的模型。同时保持expendA和expendB不变而改变shareA,这讲得通吗?
(vi)(要求有微积分知识)在第(V)部分的模型中,保持prtystrA和expendA不变,求出expendB对voteA的偏效应。在expendA=300和expendB=0时进行计算,并评论你的结论。
第6题
以二叉链表作为二叉树的存储结构,编写以下算法:
(1)统计二叉树的叶结点个数。
(2)设计二叉树的双序遍历算法(双序遍历是指对于二叉树的每一个结点来说,先访问这个结点,再按双序遍历它的左子树,然后再一次访问这个结点,接下来按双序遍历它的右子树)。
(3)计算二叉树最大的宽度(二叉树的最大宽度是指二叉树所有层中结点个数的最大值)。
(4)用按层次顺序遍历二叉树的方法,统计树中具有度为1的结点数目。
(5)求任意二叉树中第一条最长的路径长度,并输出此路径上各结点的值。
(6)输出二叉树中从每个叶子结点到根结点的路径。
第7题
A.9/25
B.6/25
C.3/5
D.2/5
第8题
A.干扰机器识别图像的新方法
B.新算法助机器学习抵抗干扰
C.机器学习是人工智能的核心
D.机器学习大数据训练的方法



















